分析 7zip 漏洞 CVE-2024-11147(WIP)
分析一下 7zip 漏洞 CVE-2024-11477/ZDI-24-1532,查看 ZDI 公告 提取到关键点:
- 24.07 修复,之前的版本有问题:那么我们 DIFF 24.07 和 24.06 的代码
- 漏洞出现在 Zstandard 解压的代码中
DIFF
用 beyond compare 对比以后找到 C\ZstdDec.c 这个文件有如下修改:
>> git diff D:\Downloads\7z-compare\2406\C\ZstdDec.c D:\Downloads\7z-compare\2407\C\ZstdDec.c
diff --git "a/D:\\Downloads\\7z-compare\\2406\\C\\ZstdDec.c" "b/D:\\Downloads\\7z-compare\\2407\\C\\ZstdDec.c"
index fd0dbda..ef9eca3 100644
--- "a/D:\\Downloads\\7z-compare\\2406\\C\\ZstdDec.c"
+++ "b/D:\\Downloads\\7z-compare\\2407\\C\\ZstdDec.c"
@@ -1,5 +1,5 @@
/* ZstdDec.c -- Zstd Decoder
-2024-05-26 : the code was developed by Igor Pavlov, using Zstandard format
+2024-06-18 : the code was developed by Igor Pavlov, using Zstandard format
specification and original zstd decoder code as reference code.
original zstd decoder code: Copyright (c) Facebook, Inc. All rights reserved.
This source code is licensed under BSD 3-Clause License.
@@ -1308,8 +1308,10 @@ FSE_Decode_SeqTable(CFseRecord * const table,
in->len--;
{
const Byte *ptr = in->ptr;
- const Byte sym = ptr[0];
+ const unsigned sym = ptr[0];
in->ptr = ptr + 1;
+ if (sym >= numSymbolsMax)
+ return SZ_ERROR_DATA;
table[0] = (FastInt32)sym
#if defined(Z7_ZSTD_DEC_USE_ML_PLUS3)
+ (numSymbolsMax == NUM_ML_SYMBOLS ? MATCH_LEN_MIN : 0)
根据这个修改我们可以大胆推测,这里是从字节流中读出 1 字节的某个结构的数量,之前没有验证这个数量是否超出了正常的范围,所以产生了漏洞。 接下来我们要验证这个的猜测,并且构造一个 POC 出来。
先要了解一下 .zst 文件格式的信息,可以搜到一个 facebook 官方的文档 ,阅读后得知:
- .zst 文件是由多个 frame 组成的, frame 以魔法数 0xFD2FB528 开头
- 每个 frame 可以包含 1-n 个 data_block,data_block 有多种类型,储存压缩数据的是 Compressed_Block
- Compressed_Block 包含 Literals Section 和 Sequence Section 两部分
再来结合代码,被修改的函数是 FSE_Decode_SeqTable, 仅在 ZstdDec1_DecodeBlock 函数中有 3 处引用,且这三处引用相邻,应该是解码 data_block 的一个步骤。结合文档分析代码,发现函数 ZstdDec1_DecodeBlock 实际上在处理 Compressed_Block,函数 FSE_Decode_SeqTable 在处理 Sequences Section, 被修改的代码行,是在解码 Compressed_mode 为 RLE_Mode 的 sequence 数据,读到 sym 变量的值是 Literals_Length_Table/Offset_Table/Match_Length_Table 的内容,是攻击者可控的,table[0] = sym 是将其保存到了一个 CZstdDecFseTables 结构体,以供后续使用。接下来分析这个值在哪里使用,目前高度怀疑是后面紧接着会调用的 Decompress_Sequences 函数中,但是此函数用了大量的宏,直接分析起来很不方便,先用 VC 编译器的功能得到一份预处理之后的代码
> # Visual Studio Developer Powershell 中运行,否则可能报错没找到 cl
> cl /P c\ZstdDec.c
> # 可选步骤,只是格式化代码,如果装 VS 时候没有选装 llvm 可能会缺少 clang-format
> clang-format ZstdDec.i > ZstdDec.i.c
阅读以后就可以证实,存入 CZstdDecFseTables 的值,就是在 Decompress_Sequences 中使用的,Decompress_Sequences 是 tANS/FSE 解码算法的实现,这个算法是 zstd 压缩率能高与其他仅基于 huffman 编码的压缩软件的核心因素,我认为还比较复杂,不过对于我们漏洞分析的目标来说,也不需要了解很多,参考 understanding-ans-coding-through-examples-d1bebfc7e076 可以得到解码的操作重点如下:
- 解码需要三个输入参数:状态 x、速查表 table、字节流 bitStream
- 速查表存储了每个状态对应的:符号 S, 以及状态转移需要的参数 y、k(使用方式例如 table[x].S、table[x].y、table[x].k,但是实际算法是有优化的,S、y、k 三个值被存入了同一个 DWORD 中,用位操作代替了这些成员变量访问)
- 解码涉及到多轮迭代,每轮都会:
- 根据当前状态从速查表查出解码的符号 S(解压后得到的原始值)
- 将 x 转移到新状态:状态转移需要 x、y、k、bitStream 参与运算
- 回顾一下 Sequence Section 的结构:
-
Sequences_Section_Header[ Literals_Length_Table][ Offset_Table][ Match_Length_Table]bitStream - Xxxxx_Table 存储的就是速查表,因为存储了 Literals_Length、Offset、Match_Length 三种数据,所以是三个速查表
- bitStream,其实是 Literals_Length、Offset、Match_Length 三个数据流交叉存放在一起形成的一个数据流
-
- 另外解码时 bitStream 是从最后一个字节开始,反向使用的。因为编码时是将状态信息正向写入的 bitStream,解码的时候要从最后一个状态开始(编码器眼里的最后一个),反向恢复,恢复出的原数据也是反向的
- 至于为什么这样解码可以解压数据,x、tab、bitStream、y、k 又都是怎么来的,感兴趣的话大家可以深入去学习 tANS 算法,这里就不展开了,只需要知道这个算法的解码就是在做这些操作即可
ℹ️ 如果想深入了解 tANS/FSE,如下资料可以参考:
- https://www.cnblogs.com/zblade/p/14338758.html
- https://bjlkeng.io/posts/lossless-compression-with-asymmetric-numeral-systems/
- https://kedartatwawadi.github.io/post–ANS/
- https://fastcompression.blogspot.com/2013/12/finite-state-entropy-new-breed-of.html
- http://cbloomrants.blogspot.fr/2014/02/02-18-14-understanding-ans-conclusion.html
了解了这些,就可以知道,攻击者可控的数据 sym,就是速查表里存储的内容,解码的时候确实会用到它,不过这里要注意速查表里的元素是 32 比特的,而我们只能控制这 32 位的低 8 位,再结合代码来看,Decompress_Sequences 函数中的临时变量 state_ll、state_of、state_ml 是从速查表中查到的值,它们的最低字节又会传递到 of_code、matchLen、litLen。(也就是说速查表存储的 32 比特元素,低 8 位存放的是符号 S)而 of_code、matchLen、litLen,又在几处内存访问的地方被当作索引/长度来使用,如果在这些内存访问的地方,也没有检查索引/长度的合理性的话,就会产生内存访问越界了。例如:
//from ZstdDec.i.c
//...
static const UInt32 k_SEQ_LL_BASES[36] = {
0, 1, 2, 3, 4, 5, 6, 7, 8,
9, 10, 11, 12, 13, 14, 15, 16, 18,
20, 22, 24, 28, 32, 40, 48, 64, 0x80,
0x100, 0x200, 0x400, 0x800, 0x1000, 0x2000, 0x4000, 0x8000, 0x10000};
#line 286 ".\\ZstdDec.c"
static const Byte k_SEQ_LL_EXTRA[36] = {
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1,
1, 1, 2, 2, 3, 3, 4, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16};
//....
const unsigned extra = k_SEQ_LL_EXTRA[litLen];
litLen = k_SEQ_LL_BASES[litLen];
ℹ️ 也可以通过阅读原代码,在宏定义中发现速查表中存储的信息的格式:
#define FSE_REC_LEN_OFFSET 8
#define FSE_REC_STATE_OFFSET 16
#define GET_FSE_REC_SYM(st) ((Byte)(st))
#define GET_FSE_REC_LEN(st) ((Byte)((st) >> FSE_REC_LEN_OFFSET))
#define GET_FSE_REC_STATE(st) ((st) >> FSE_REC_STATE_OFFSET)
使用 litLen 作为下标访问了两个数组,两个数组的长度都小于 litLen 可能的最大取值,很可能可以构造出能触发越界读的样本。
下面我们就结合调试器,构造出对应的样本,触发越界访问。先从源码构建出可执行文件,整个项目包含多个可执行文件,我选择了 7zcl.exe、7z.dll 作为调试目标,用 nmake 来构建,构建 Debug 版本以方便调试,方案是参考 stackoverflow nmake-how-do-i-force-a-debug-build-7zip 。
- 修改 CPP/7zip/UI/Client7z/Client7z.cpp:64 的代码
DEFINE_GUID_ARC (CLSID_Format, 0xe)- 0xe 是 zstd 文档对应的 arc ID
- 可以在 CPP/7zip/Archive/ZstdHandler.cpp 的
REGISTER_ARC_IO宏调用中找到
- 修改 CPP/Build.mak 的 CFLAGS 和 LFLAGS,以构建调试版的可执行文件以及对应的 .pdb 文件:
- CFLAGS 中的 -O1 -O2 都改成 -Od 禁用优化
- CFLAGS 加入 /Zi 以生成调试符号
- CFLAGS 去掉 -W4 和 -Wall,以解决编译过程中由于警告造成的编译失败
- LFLSGS 加入 /DEBUG
- 在 VS Developer Powershell 执行构建操作
> pushd > # 构建client7z.exe > cd CPP\7zip\UI\Client7z > nmake > popd > # 构建 7z.dll > cd CPP\7zip\Bundles\Format7zF > nmake > # 拷贝 7z.dll 7z.pdb 到 client7z.exe 同目录 > copy .\o\7z.dll ..\..\UI\Client7z\o\ > copy .\o\7z.pdb ..\..\UI\Client7z\o\
有了 Client7z.exe 和 7z.dll 就可以调试了,对于有源码的场景,我喜欢用 VS 来调试:
- 用 VS 的 Open Folder 功能将 7zip 的源码目录作为项目打开
- 在 VS 的解决方案浏览器,找到 Client7z.exe (在 CPP/7zip/UI/Client7z/o/Client7z.exe)
- 右键菜单 -> Set As Startup Item
- 右键菜单 -> Add Debug Configuration -> Default
- 在自动打开的 lauch.vs.json 中加入命令行配置
args{ "version": "0.2.1", "defaults": {}, "configurations": [ { "type": "default", "project": "CPP\\7zip\\UI\\Client7z\\o\\7zcl.exe", "projectTarget": "", "name": "7zcl.exe", "args":["7zcl.exe", "x", "poc.zst"], } ] }
这样配置好以后,在 VS 中点击开始调试,VS 就会用指定的命令行为我们启动一个 7zcl.exe 并开始调试了。参数中指定了用 7zcl.exe 来解压一个 poc.zst 文件,我们还需要构造出这个 poc 文件。我的构造方式是找到一个小的 .zst 文件,在它的基础上进行修改。所以我安装了压缩程序 zstd 压缩了一个随便找的小文件,得到下面这个 poc.zst 文档(base64 编码的数据)。
KLUv/WSBAJ0HAFJNLiUgjegBs3wDbJDe4r8UR0hA5BmkXH0Jy6Cv+C63gaF/CdCKP4IGzBhJZOKUqtIw7n20LSBY3uBwWZSIl6jJcpCpKCCYttankcF0jCQycelqTFPTw5UYKgg9+Quz+k+L7D+0xU4we2fpP+lo+E9CaGFW3b/pbGySfuPgbfN4At3MIB0AoGin69MidMwSqMkZFESlIF1t4b5wb6c/QtDCf8wG2ulGNJ+E4CNaZ786OsHs3skrTTv9TBoFFQBCO8DJOEBhX52cCLeAtQPAymDVhpcMuG58YyM4JrMaHiov0xxbDWxBoGAlONs9w+AyrI8oe8zKBHY=
ℹ️ 也可以直接使用这个 CyberChef 页面下载 .zst 文档
接下来我调试了 Client7z.exe 解压 poc.zst 的过程,发现 poc.zst 的 Symbol compression modes (0xC7 偏移处) 全为 0。
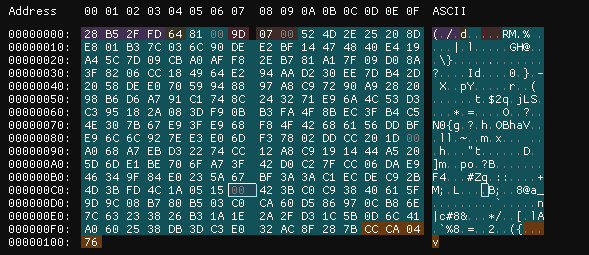
为了触发漏洞,我把他改成 0b01010100,再把后面 3 字节的数据全改成 0xff。
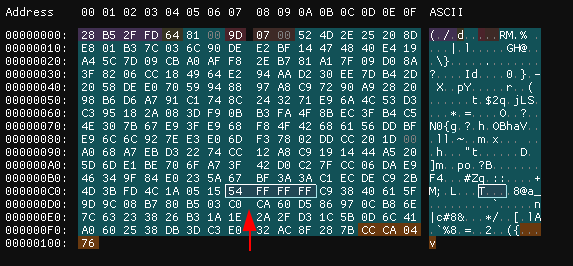
改完后再次调试,发现已经可以触发越界读。
// ZstdDec.c:2197
size_t litLen = GET_FSE_REC_SYM(STATE_VAR(ll));
if (litLen)
{
// if (STATE_VAR(ll) & 0x70)
if (litLen >= 16)
{
const unsigned extra = BASES_TABLE(SEQ_LL_EXTRA) [litLen]; // 运行到这里 litLen 为 0xff 已经超出了 k_SEQ_LL_EXTRA 数组的边界
litLen = BASES_TABLE(SEQ_LL_BASES) [litLen]; // 这里也是
#ifdef Z7_ZSTD_DEC_USE_64BIT_LOADS
虽然可以触发漏洞了,但是由于这两个数组都是 static 数组,存储在 7z.dll 的 .rdata 段的,越界读刚好可以读到其他只读数据,不会触发崩溃,一个不会触发崩溃的 POC,总感觉差点什么,而且公告里说这个漏洞是可以造成一个 underflow 的,和我们分析的情况也明显不一样,所以接下来我们继续分析看怎么才能触发崩溃/ underflow。
未完待续
Typo
分析漏洞的过程中还在 7z 项目中发现一个 typo,有空去刷一个 COMMIT 🙃
// CPP/7zip/Archive/ArchiveExports.cpp:50
static int FindFormatCalssId(const GUID *clsid) // Calss -> Class